0
发表咨询在线!

发布时间:2022-04-09所属分类:计算机职称论文浏览:1688次
摘 要: 摘要: 为了提高电网数据处理的安全性和效率,提出基于 Hadoop 的智能电网时序大数据处理方法。依据智能电网时序大数据简析,结合 Map、Reduce 及 Partition 三个函数具备的过滤器和工厂法以及监听器等一系列模式,实现数据清洗处理。依据分布式计算思想,结合近邻分类

摘要: 为了提高电网数据处理的安全性和效率,提出基于 Hadoop 的智能电网时序大数据处理方法。依据智能电网时序大数据简析,结合 Map、Reduce 及 Partition 三个函数具备的过滤器和工厂法以及监听器等一系列模式,实现数据清洗处理。依据分布式计算思想,结合近邻分类法和 Map - Reduce 模型设计的并行分类混合法,实现数据分类处理。对分类数据进行安全存储,通过消息摘要算法针对需要存储的智能电网时序大数据生成相应数字摘要; 根据密钥生成函数获取随机密钥,同时利用上述密钥针对待存储数据实行加密,获取对应密文。针对获取的随机密钥实行信息隐藏处理; 把密文存储至云中; 当密文成功存储至云之后,把获取的密钥和数字摘要两种信息并同文件名至 HBase 中,实现数据存储。仿真结果表明,上述方法具有较强的安全性与时效性。
关键词: 智能电网; 时序大数据; 处理
1 引言
分布全网的各种类型信息数据采集装置生成了大规模时序数据,关于此类数据的存储、处理等均面临着严峻的挑战[1 - 3]。由此,针对智能电网中的时序大数据进行高效处理有着十分关键的作用和重要的意义。
曲朝阳[4]等人将 Spark 应用至电力设备监测数据可视化处理中。过程中,以快速提取大数据环境下电力监测数据整体状态信息为目的,基于 Spark 大数据计算平台,设计并构建了设备状态评价指标体系和模糊 C 均值聚类算法下的电力设备状态数据提取法。对数据具备的多维和时序等特征,构建三维平行散点图,实现数据可视化展示,完成电力设备状态信息可视化处理。喻宜[5]等人以解决电力大数据背景下大规模时序数据无法高效处理的问题为目的,结合当前分布式技术框架设计并构建真正意义上的 GAIA 大规模时序数据管控平台,以此保障系统具备稳定性与可靠性。根据具备可配置层次关系架构的模型中心解决大规模测点管控问题。依据时间分片和事件驱动下前置数据采集平台解决大规模终端实时数据采集处理问题。张宇航[6]等人指出,智能电网具备的数字化建设能够提供大规模数据信息,深度学习发展能够为数据价值提取提供可靠途径。在研究过程中,先对深度学习发展史和基础结构进行分析,并归纳了深度学习理论基础与技术体系; 然后与电力系统实际需要相结合,将图像数据和时空数据了两种类型的数据当作基础,综合描述了深度学习在电力数据处理中的应用和具体价值,同时给出了一些相关发展建议。
电网时序数据具有规模大、实时性要求高和访问方式多变等特点,对其进行处理需要注意的点比较多,其中包含安全性、效率。为此,提出基于 Hadoop 的智能电网时序大数据处理方法。
2 基于 Hadoop 的智能电网时序大数据处理
2. 1 智能电网时序大数据
实际生活中,智能电网时序大数据通常指的是根据设备或者仪表产生,利用传感器进行采集,和某个对象或者设备存在具体关联性,在事件上先后关联的一类数据。详细如图 1 所示,其中包含的电压等即为典型时序数据。
2. 2 数据清洗
在基于 Hadoop 的智能电网时序大数据处理方法中,大数据清洗是不可或缺的一个步骤。针对 Map 和 Reduce 及 Partition 三个函数均进行了精心设计,通过 xml 配置,实现对应的清洗类动态收集和清洗规则设定等。
数据清洗过程中,Map 函数是该架构中最为核心的部分,把数据由原始状态清洗到可利用数据。Map 设计中使用了过滤器和工厂法以及监听器等一系列模式,能够使清洗系统具备良好的扩展性。图 2 为 Map 函数核心设计示意图。
图 2 中,LogProcess 类主要负责 Map 阶段基础性的配置文件前期准备以及使用方案调用 Handler 类,梳理实际数据处理逻辑。其中,Handler 类为处理逻辑中实际控制类,均需在 Map 阶段初始化环节完成。实际处理过程中根据 Handler 调用图 2 中的流程部分完成: 利用 FilterChain 以相似管道的模式进行逐步解析与清洗,FilterChain 主要作用为配置过滤条件。在 Map 设计过程中,所有类都使用了可配置方式,能够基于实际数据清洗需求任意替换与修改。
在日志处理过程中,原始日志利用 JournalClean 类实现基础处理,从而生成部分基础字段,同时以 table 形式保存至 Journal,以此构成 Journal 日志类,把该类在过滤器链中依据具体要求下的逻辑实行解析,生成最终所需字段,利用 JournalWriter 日志写入相应文件,将最终数据输出。
2. 3 数据分类
依据分布式计算思想,解决智能电网时序大数据分类问题,根据近邻分类法具备的优势,结合 Map - Reduce 模型和其融合设计一个并行的分类混合法—PCHA。
输入: 要实现 PCHA 算法,构建接口提供 Map 函数与Reduce 函数,并表明输入、输出以及其它运行参数。利用输入环节把大数据集合分解成若干个独立的数据集合,便于接下来的处理,在此设置为M'份数据集合,提交至 JobTracker 之后,利用对应的 TaskTracker 执行任务。
Map: 在 Map - Reduce 模型中通常分解一个大数据集变为小数据集合,该环节是针对每一组分解数据集合的{ ke, va } 对实行映射操作,此时 TaskTracker 调用空闲数据资源执行 Map 与 Reduce 任务。Map 过程重点是针对分类数据集合实行键值映射操作,任务基于各属性规范化操作,同时依据重要性并获得加权欧式距离结果,获取( ( 节点,属性) ,( 相似程度) ) 键值对,基于相似程度实现归类。
Reduce: 该环节主要责任为遍历所有 Map 环节处理之后生成的中间结果集合,依据同一( 节点,属性) 值的排序和归纳,统一将( ( 节点,属性) ,( 相似程度) ) 输出,基于相似程度实现并行分类。
输出: 该环节是和输入环节相呼应的,也就是功能为针对 Reduce 环节的输出结果集合实行输出操作,同时将输出保存到指定位置,该环节获取的即为 PCHA 算法运行所得的分类结果集合,方便下一步安全存储处理。
2. 4 数据安全存储
在基于 Hadoop 的智能电网时序大数据存储处理中,根据云安全实现数据的安全存储。因云安全核心为密码技术与加固技术,由此能够通过密码技术保护智能电网时序大数据存储具有保密性与完整性[9 - 10]。其中,摘要信息为消息签名操作之后所得数据,密文为数据加密之后所得数据,密钥信息为针对数据加密过程中用到的密钥实行信息隐藏之后所得数据。
综上,数据加密存储的过程可表示以下几步:
步骤 1: 生成摘要,通过消息摘要算法针对需要存储的智能电网时序大数据生成相应数字摘要。
步骤 2: 加密数据,根据密钥生成函数获取随机密钥,同时利用该密钥针对待存储数据实行加密,获取对应密文。
步骤 3: 随机密钥隐藏,针对上述获取的随机密钥实行信息隐藏处理。
步骤 4: 存储密文,把密文存储至云中。
步骤 5: 保存有关信息数据,当密文成功存储至云之后,把上述步骤中获取的密钥和数字摘要两种信息并同文件名至 HBase 中,实现数据保存。
随机密钥信息隐藏过程中,以解决对称加密法密钥管理相关问题为目的,要针对随机密钥实行信息隐藏操作。加密为一种非常高效的信息隐藏策略。由此,为了针对随机密钥实行信息隐藏处理,设计如图 3 所示的密钥隐藏策略。
在上述策略中,通过数据源具备的各种属性和一个填充数即可生成摘要信息,然后利用 Hash 函数生成数据加密所需密钥。其中,属性中能够包括用户密码数据,在用户修改密码之后,可以使随机密钥也随之修改,无需重加密,能够有效提升效率。
结合随机填充数目的为避免字典攻击与预先计算攻击等安全问题。以增强保密性为目的,数据源属性组合信息和详细 Hash 应事先保密。以变电站为例,该变电站属性将 Substation 类属 性 当 作 标 准,设计的密钥生成架构如图 4 所示。
为了 把 密 钥、摘要两种信息存储至 HBase 中,对 表MetaTable 结构进行设计。
其中,MetaTable 主要分为三列,分别为行关键字 RowKey 应用至存储文件名称,时间戳 Timestamp 和列族 Metadata( 包括密钥信息与摘要信息的保存标签) 。除此之外,针对无需进行加密的数据而言,使用 hiddenKey 是全 0 进行区分。
采用 HBase 主要原因为电网中的数据采集及存储频率均非常高,一般关系数据库无法承受此种压力。HBase 查询效率不会随着数据库中的数据量规模变大降低,其为一个具有可伸缩性能的分布式存储系统。
数据读取过程为:
步骤 1: 数据读取,在分布式文件系统中读取密文,在 HBase 中将有关数据读取出来。
步骤 2: 确定数据类型,基于密钥信息,判断分布式文件系统中数据需要解密与否。假设密钥信息为 0,那么表明数据为明文,无 需 进 行 解 密,直 接 到 步 骤 4; 反 之,表 明 需 要解密。
步骤 3: 得到随机密钥,通过数据源属性,也就是密钥信息得到密 钥,同时针对密钥信息实行信息恢复获取随机密钥。
步骤 4: 对数据进行解密,利用上述获取的密钥针对密文实行解密。
步骤 5: 对数据完整性进行检查,生成密文数字摘要信息,同时和步骤 1 中的摘要信息进行对比,确定数据完整性。假设不一致,那么表示云中数据已经被篡改; 反之,说明数据正常。
3 实验结果与分析
为了验证基于 Hadoop 的智能电网时序大数据处理方法有效性,进行一次实验。实验在某省电科院实验室所搭建的 Hadoop 并行计算平台上完成,该平台由 23 个节点构成。节点物理配置的 CPU 为 8 核、内存为 32G,硬盘为 300G,网络为千兆以太网。实验过程中,文件备份为 3。
相关知识推荐:大数据方面的期刊杂志
实验分别以 CPU 利用率和数据安全性为验证指标。其中,以验证所提方法 CPU 利用率为目的,在大小不一的数据文件下开展实验,为避免时间因素导致实验结果带来的主观性,本次实验将分别在三台电脑上进行,并在规定时间内进行检测,测试时间为 19: 15 ~ 19: 33。依据智能电网数据量存在差异大的特性,分别取文件大小为 10MB、50MB、500MB 的条件下进行实验,所得实验结果如 6 所示。
分析图 5 可知,基于 Hadoop 的智能电网时序大数据安全存储处理与直接存储耗时相差不大,表现出了良好的运行性能,存储处理效率高。主要原因为数据存储过程中网络传输时间占据了主导地位,其它时间在数据量比较大时影响不是很大,且数据的清洗和分类均为高效率存储奠定了基础,有效提高了电网时序大数据存储速度。
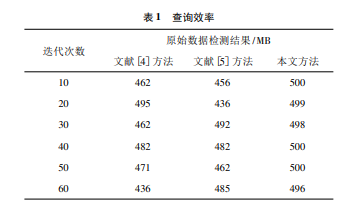
为进一步验证本文方法的处理安全性,本次实验将在 500MB 的数据文件中加入字典攻击与预先计算攻击,并设置攻击数据和异常数据大小为 20MB,检验本文方法是否能够有效、安全、准确的查询到系统原始数据,以此分析所提方法的安全性。实验结果如表 1 所示。
由表 1 可知,所提方法可高效抵御攻击,保障数据安全性。在数据加密存储过程中,结合了随机填充数目的为避免字典攻击与预先计算攻击等安全问题,并以增强保密性为目的,数据源属性组合信息和详细 Hash 也做了保密。
4 结束语
鉴于现实需求,提出基于 Hadoop 的智能电网时序大数据处理方法。在数据处理过程中,有效结合了数据清洗、分类、安全存储几个部分,并通过实验对该方法进行测试,结果显示,该方法抗攻击性能强,且耗时少,是一种可行的电网数据处理方法。下一步可将跨节点计算并行化方面当作重点进行研究,进一步提高数据处理效率。——论文作者:孙利宏
参考文献:
[1] 贺红燕. 基于大数据的智能电网关键技术研究[J]. 电源技术,2016,40( 8) : 1713 - 1714.
[2] 陈敬德,盛戈皞,吴继健,等. 大数据技术在智能电网中的应用现状及展望[J]. 高压电器,2018,54( 1) : 35 - 43.
[3] 葛磊蛟,王守相,瞿海妮. 智能配用电大数据存储架构设计[J]. 电力自动化设备,2016,36( 6) : 194 - 202.
[4] 曲朝阳,熊泽宇,颜佳,等. 基于 Spark 的电力设备在线监测数据可视化方法[J]. 电工电能新技术,2016,35( 11) : 72 - 80.
[5] 喻宜,吕志来,齐国印. 分布式海量时序数据管理平台研究[J]. 电力系统保护与控制,2016,44( 17) : 165 - 170.
[6] 张宇航,邱才明,杨帆,等. 深度学习在电网图像数据及时空数据中的应用综述[J]. 电网技术,2019,43( 6) : 1865 - 1873.
[7] 李俊楠,李伟,李会君,等. 基于大数据云平台的电力能源大数据采集 与 应 用 研 究[J]. 电 测 与 仪 表,2018,56 ( 12 ) : 104 - 109.
[8] 余容,黄剑,何朝明. 基于 SM4 并行加密的智能电网监控与安全传输系统[J]. 电子技术应用,2016,42( 11) : 66 - 69.
[9] 张思佳,顾春华,温蜜. 智能电网中的数据聚合方案分类研究[J]. 计算机工程与应用,2019,55( 12) : 83 - 89.
[10] 张子栋,张杰敏,茅剑. 大数据处理警示性图像颜色纹理特征选取仿真[J]. 计算机仿真,2019,36( 5) : 434 - 437,470.
婵犵數濮烽弫鍛婃叏閻戣棄鏋侀柛娑橈攻閸欏繐霉閸忓吋缍戦柛銊ュ€块弻锝夋偄瀹勬壆鐩庨梺鍏兼緲濞尖€愁嚕閸洖閱囨繛鎴灻‖澶娾攽閻愬弶鍣藉┑顔肩仛缁岃鲸绻濋崶顬囨煕鐏炲墽鐓瑙勬礋濮婃椽宕ㄦ繝搴㈢杹婵炲瓨绮岄悥鐓庮嚕婵犳艾惟闁冲搫鍊告禍鐐烘⒑缁嬫寧婀扮紒瀣灴椤㈡棃鏁撻敓锟�:闂傚倸鍊搁崐鎼佸磹閹间礁纾瑰瀣捣閻棗銆掑锝呬壕閻庤娲﹂崹鍫曠嵁閹邦厽鍎熼柕蹇ョ磿瑜板潡姊洪悷鏉挎倯闁伙綆浜畷鐟懊洪鍕厬闂婎偄娲︾粙鎺楁偂閻斿吋鐓忛煫鍥э攻閸ゅ鎲搁悧鍫濈瑨缂佲偓閸曨垱鐓熸俊顖濆亹鐢盯鏌i幘瀛樼闁哄瞼鍠愮€佃偐鈧稒蓱闁款參姊洪崫鍕靛剳闁哥姵鐗犲璇测槈濮橈絽浜鹃柨婵嗛娴滅偛顭胯閸撶喖寮婚弴銏犵倞鐟滃秹顢旈鐘亾濞堝灝娅橀柛锝忕到閻g兘宕奸弴妞诲亾閺嶎収鏁婇柤鎭掑劚绾惧啿鈹戦纭峰伐妞ゎ厼鍢查悾鐑芥偄绾拌鲸鏅濋梺闈涙处婵℃悂宕堕妸褍骞愰梺璇茬箳閸嬬娀顢氳閸┾偓妞ゆ帊鑳舵晶杈╃磽閸屾稒宕岄柟宕囧仱婵$兘濡疯閻涱喖鈹戦悩顔肩伇婵炲鐩鐢割敆閸曨偆鏌ф繝闈涘€搁幉锟犲煕閹烘嚚褰掓晲閸噥浠╅柣銏╁灡閻╊垶寮婚悢鍝勬瀳闁告鍋樼花钘夆攽閳ュ啿绾ч柛鏃€鐟ラ锝夊箻椤旇棄浜归梺褰掝暒閻掞妇绱炲Δ鍛拻濞达絽鎲¢幆鍫ユ煕閻曚礁浜伴柟顔ㄥ洤骞㈡繛鍡樺灣缁楀姊洪幐搴g畵婵☆偅绋撶划缁樸偅閸愨晝鍘遍梺鏂ユ櫅閸犳艾鈻撳▎鎾村€垫慨姗嗗幗缁舵煡妫佹径瀣瘈濠电姴鍊搁鈺呮煕閺傝鈧繂螞娴g懓绶為柟閭﹀幘閸欏棗鈹戦悩缁樻锭婵☆偅鐟╅獮鏍箛閻楀牏鍘遍梺鍝勫€归娆撳磿閹邦儮搴ㄥ炊瑜濋煬顒併亜閵忥紕鈽夋い顐g箞楠炴垿骞囬浣稿壍闂傚倸鍊风粈渚€骞栭锔藉剹濠㈣泛鏈畷鍙夌節闂堟稒顥犻柡鍡檮閵囧嫯绠涢幘鏉戞婵犳鍨遍幐鎶藉蓟濞戞ǚ妲堟慨妤€鐗嗘慨娑欑箾鐎涙ḿ鐭嬮柣妤冨Т椤繒绱掑Ο鑲╂嚌闂侀€炲苯澧撮柛鈹惧亾濡炪倖甯掗崐鍛婄濠婂牊鐓犳繛鑼额嚙閻忥妇鈧娲忛崹钘夌暦閵婏妇绡€濞达綀娅i悾楣冩⒒娴h櫣甯涢柛鏃€鐗曞玻鍨枎閹寸姷鐣堕悷婊冪箳濡叉劙骞掑Δ濠冩櫓闁荤喐鐟ョ€氼參鎮甸弴銏♀拺闂傚牊绋撴晶宕囩磽瀹ュ嫮顦﹂柣锝呭槻椤粓鍩€椤掍椒绻嗛柟闂寸劍閺呮粎绱撴担鐧镐緵婵☆偁鍔戝濠氬磼濮橆兘鍋撴搴㈩偨婵﹩鍏楃紓姘舵煠婵劕鈧劙宕戦幘缁橆棃婵炴垶姘ㄩ崝顖炴倵鐟欏嫭纾搁柛銊︽そ婵″爼鏁愭径濠勵槰闂侀潧臎鐏炶姤娅嶉梻鍌氬€烽懗鑸电仚缂備胶绮敋閾荤偤鎮归幁鎺戝鐎规洘鐓¢弻娑㈠焺閸忥附绮嶇粋宥呪堪閸喓鍘甸梻渚囧弿缁犳垿寮稿☉銏$厸閻庯綆浜妤呮婢跺绡€濠电姴鍊搁弳娆撴煃闁垮鈷掔紒杈ㄥ笚濞煎繘濡搁敃鈧棄宥夋⒑閻熸澘妲婚柟鍐茬箻钘濋柣妤€鐗婇崕鐔镐繆椤栨粎甯涙繛鍛暣濮婂宕掑▎鎴濆闂佽鍠栭悥鐓庣暦濠靛棭鍚嬮柛婊€鐒︾€靛矂姊洪懞銉冾亪藝娴犲鍚归柡鍥ュ灪閻撴瑩鏌熼娑欑凡鐞氭岸姊虹粙娆惧剰閻庢矮鍗冲濠氭晲婢跺﹦顔掗梺鎯ф禋閸嬪懎鐣烽崘宸富闁靛牆妫欓悡銉︺亜閿旇鐏﹂柍銉︽瀹曟﹢顢欓崲澹洦鐓曢柍鈺佸枦娓氭稒鎱ㄦ繝鍌涘仴婵﹨娅g划娆忊枎閹冨闂備礁鎲″鐟懊洪悢鍏兼櫜闁绘劖绁撮弨浠嬫倵閿濆簶鍋撻娑欐珚闁哄苯绉瑰畷顐﹀礋椤愮喎浜惧┑鐘宠壘閻鏌涢埄鍐︿粶闁衡偓娴犲鐓熼柟閭﹀幗缂嶆垿鏌h箛銉х暠闁伙絾绻堥弫鎰板川椤旈棿娣梻浣筋嚃閸犳岸宕戦妶澶婅摕闁靛ě鈧崑鎾绘晲閸愩劌顬嗙紓浣靛妼椤嘲顫忓ú顏勪紶闁告洦鍓欓ˇ鈺侇渻閵堝啫濡兼俊顐n殜閸┿垹顓奸崱娆戠槇闂佸憡娲忛崝灞剧閻愵剛绠鹃柛顐g箘娴犮垽鏌$€c劌鈧洟鈥﹂懗顖fЪ濡炪們鍔岄敃顏堟偘椤曗偓瀹曞崬鈽夊Ο鑲╂綁闂備礁澹婇崑鍛崲瀹ュ懇缂氬┑鐘叉处閳锋垿鏌¢崒妯哄姕婵炲懎鎳橀弻娑㈡偆娴i晲鍠婂銈冨灪濮婂湱鈧絻鍋愰埀顒佺⊕鑿ら柟椋庣帛缁绘稒娼忛崜褍鍩岄梺纭咁嚋缁绘繈鐛崱娑橀唶闁靛濡囬崢杈ㄧ節閻㈤潧孝濠殿垶浜跺畷鐑筋敇閻愯尙鏌ч梻鍌氬€风欢姘缚瑜戦崳褰掓⒑缁嬫寧婀扮紒顔兼湰閺呰埖銈i崘鈹炬嫽婵炶揪缍€濞咃絿鏁☉銏$厱闁哄啠鍋撴繛鍙夌墳閻忔帗绻濋悽闈浶㈡繛灞傚€濋幃鍧楊敋閳ь剟寮诲☉妯锋婵☆垰鍚嬮幉濂告⒑缂佹ɑ灏靛┑顔惧厴閹偓妞ゅ繐鐗嗙痪褔鏌涢…鎴濇灕闁糕晝鍋炵换婵嬪煕閳ь剟宕掑顒傘偖闂備礁鎼惌澶岀礊娴i€涚箚闁绘垼妫勫敮闂佹寧娲嶉崑鎾寸箾閸噥娈滄慨濠冩そ瀹曨偊宕熼浣瑰缂傚倷绀侀鍡涘垂閸ф鏄ラ柕蹇婂墲閸庣喖鏌曟繛鍨姢闁汇倐鍋撳┑锛勫亼閸婃牜鏁幒妤€纾瑰瀣椤洘鎱ㄥ璇蹭壕濠殿喖锕︾划顖滅箔閻旂厧鐒垫い鎺嗗亾瀹€锝堝劵椤︽煡鎽堕悙缈犵箚闁靛牆鎳忛崳褰掓煟閵堝骸鏋涢棁澶愭煕韫囨挸鎮戠紓宥嗗灩缁辨帡鎮╅棃娑欑亪闂佽鍠楅〃鍛村煡婢跺ň鏋嶉柧蹇e亜閻忥箓鏌涢幒鎴姛闁逞屽墴濞佳囧箺濠婂懎顥氬┑鍌氭啞閸婄敻鏌ㄥ┑鍡涱€楁鐐搭殘閻ヮ亪顢橀埄鍐€愰梻鍥ь槹缁绘繃绻濋崒姘间紑婵犫拃鍐粵闁逛究鍔嶇换婵嬪礃閳瑰じ铏庢俊銈囧Х閸嬬偤宕濋弽顓炵畾闁哄啫鐗婇弲鏌ユ煕鐏炲彞绶辨繛鍏兼濮婂宕掑▎鎴М闂佸湱鈷堥崑濠囧箖瑜嶉オ浼村醇濠靛牜妲舵繝娈垮枟钃卞褍閰e畷鎴﹀箻缂佹﹩妫冨┑鐐村灦閻楁洘绂掗鈧幃妤冩喆閸曨剛顦ㄩ梺鎸庢磸閸ㄤ粙濡存担绯曟瀻闁圭偓娼欏▓鎰版⒑閸愬弶鎯堥柛鐕佸亰閹瑦绻濋崒妤佹杸闂佺粯锚閻忔岸寮抽埡浣叉斀妞ゆ梻铏庡Λ搴☆熆瑜庣换鍫濐潖閾忓湱鐭欐繛鍡樺劤閸撻亶姊洪崷顓€瑙勬櫠閽樺)锝夊箛閺夎法顔掗梺褰掝暒缁€渚€骞冮幋锔解拺缂侇垱娲栨晶鏌ユ煥閺囨娅呴摶鐐烘煕閹伴潧鏋熼柍閿嬪灩閻ヮ亪顢橀悙鏉戞闂佺粯绻嶆禍顏堝蓟閻斿吋鍋¢柣妤€鐗嗛弸鐘绘倵濞堝灝娅橀柛瀣躬閻涱喖螣閼测晝锛滃┑鈽嗗灣缁垶顢旈悢鍏尖拻濞达綀濮ょ涵鍫曟煕閿濆繒鐣垫鐐茬箻閺佹捇鏁撻敓锟�.闂傚倸鍊搁崐鎼佸磹閹间礁纾瑰瀣捣閻棗銆掑锝呬壕閻庤娲﹂崹璺虹暦缁嬭鏃€鎷呯化鏇炰壕闁割偅娲橀悡鏇熴亜閹邦喖孝闁告梹宀搁弻锝夊箳閹寸姳绮甸梺闈涙搐鐎氫即鐛幒鎴悑闁搞儴鍩栬ⅵ婵犵數濮幏鍐沪閻e奔鐢荤紓鍌欒兌缁垳绮欓幘瀵割浄闁挎洖鍊哥壕鍏兼叏濮楀牏鍒板ù婊呭亾缁绘繈妫冨☉鍗炲壈闂佽棄鍟伴崰鏍蓟閵娿儮妲堟俊顖欒娴犻亶姊虹粙娆惧剱闁圭懓娲顐﹀箛椤撶喎鍔呴梺鐐藉劥鐏忔瑩寮弽顓熲拻濞达綀顫夐妵鐔兼煕濡亽鍋㈡い銏$墬瀵板嫰骞囬鍐╂啺婵犵數鍋為崹鍫曞春閸愵喖纾婚柟鍓х帛閺呮煡骞栫€涙ḿ绠橀柡浣圭墵閺屸剝鎷呴崫銉モ叺闂佽鍠楅〃鍛村煝閹捐鍨傛い鏃傛櫕娴滅偤姊绘担鍛婂暈妞ゃ劌妫欑换娑欑節閸ヮ灛銉ッ归敐鍥┿€婃俊鎻掔墛娣囧﹪顢涢悙瀛樻殸闂佽楠搁…宄邦潖濞差亝鍋¢梺顓ㄧ畱濞堣埖绻濆▓鍨珮闁告瑥鍟锝囩矙鎼存挻鐎婚梺鐟板⒔鐞涖儵骞忕紒妯肩閺夊牆澧介幃濂稿几椤忓牊鐓欐い鏃囨閻忥妇绱掔紒妯肩疄濠殿喒鍋撻梺瀹犳閹虫捇鍩€椤掍礁顕滄い銊e劦閹瑧鎷犺娴兼劕顪冮妶鍡樺碍闁靛牏枪閻g兘宕奸弴鐐靛幐闂佸憡鍔︽禍婵嗏枔娴犲鈷掗柛灞剧懅椤︼箓鏌熺喊鍗炰簽缂侇喗妫冨濠氬Ψ閵壯屾Х闂佺懓鍚嬮悾顏堝礉瀹€鍕亗婵犻潧顑嗛悡娑㈡煕閹扳晛濡奸柍褜鍓涢弫璇茬暦閹达箑绠婚柤濮愬€曠粊锕傛⒑閸撹尙鍘涢柛鐘崇墬閹便劍鎯旈埦鈧弨浠嬫煃閽樺顥滃ù婊勭箖閵囧嫰濡搁妷顖氫紣闂佷紮绲块崗妯绘叏閳ь剟鏌曢崼婵囧櫧妞ゆ柨锕ら埞鎴炲箠闁稿﹥鎹囬幊妤呭醇閺囩偛鍋嶉梺褰掓?閻掞箓鍩涢幋锔界厱闁圭偓娼欑徊璇裁瑰⿰鈧划娆撳蓟濞戞埃鍋撻敐搴濈盎妞ゅ浚浜弻锟犲川椤撶姴鐓熷銈冨灪瀹€鎼佸春閳ь剚銇勯幒鍡椾壕濡炪値鍋勭换姗€骞栭崷顓熷枂闁告洦鍋呴悗顓㈡⒒娴g懓顕滅紒璇插€歌灋婵炲棙鎸婚崑鐔告叏濡灝鐓愰柛濠勬暬閹嘲鈻庤箛鎿冧痪缂備礁鐭佸▔鏇犳閹炬剚鍚嬮柛鏇ㄥ弾濡差喖顪冮妶鍡樼┛缂傚秳绀侀悾宄扳堪閸曨剙顎撻梺鑽ゅ枑婢瑰棝鏁嶈箛娑欌拻濞撴埃鍋撴繛浣冲洢鍋戦柛顭戝亗缁诲棝鏌涢妷銏℃珖闁活厽鎹囬弻娑㈠箻濡も偓閹虫劙鏁嶅┑瀣拺缂佸瀵у﹢浼存煟閻旀潙濮傛い銏$懄瀵板嫰骞囬鐘插箞闂佽鍑界紞鍡涘磻閸涱厾鏆︾€光偓閸曨剛鍘搁悗鍏夊亾閻庯綆鍓涜ⅵ婵°倗濮烽崑娑㈩敄婢舵劕绠栨繛鍡樻尭楠炪垺淇婇婵囶仩濞寸厧鐭傚铏规嫚閳ヨ櫕鐏嶅銈冨妼閿曨亪濡存担鍓叉僵閻犻缚娅i崝锕€顪冮妶鍡楃瑨閻庢凹鍓熼幏鎴︽偄閸忚偐鍙嗗┑鐘绘涧濡瑦鍒婇崗鑲╃閻忓繑鐗楀▍濠囨煛瀹€瀣М妤犵偞锕㈠畷妯侯啅椤旂厧唯闂傚倷娴囬褏鎹㈤幇顑╂稑鈻庨幋鐐插簥濠电偞鍨崹娲疾閺屻儲鐓曟繛鎴濆船閺嬬喖鏌熼鐣屾噰婵﹥妞介獮鎰償閵忕媭妲卞┑鐐茬摠缁姵绂嶉鍫濈畺濞村吋鎯岄弫濠囨煟閿濆懐鐏遍柟铏箞濮婃椽鏌呴悙鑼跺濠⒀冾嚟閳ь剚顔栭崳顕€宕戞繝鍥╁祦婵☆垵鍋愮壕鍏间繆椤栨粎甯涙い蹇曞枛濮婄粯鎷呴懞銉с€婇梺闈╃秶缁犳捇鐛箛娑欐櫢闁跨噦鎷�,闂傚倸鍊搁崐鎼佸磹閹间礁纾瑰瀣捣閻棗銆掑锝呬壕濡ょ姷鍋涢ˇ鐢稿极閹剧粯鍋愰柛鎰紦閻㈢粯淇婇悙顏勨偓鏍偋濠婂牆纾绘繛鎴欏灩閸ㄥ倿鏌涘畝鈧崑鐐烘偂閺囩喆浜滄い鎾跺枎閻忋儱霉濠婂懎浠﹂柕鍥у閸╋繝宕橀妸銉ョ闂備礁鎼張顒勬儎椤栫偑鈧線寮撮姀鈥充汗闂佽偐鈷堥崗娑㈠箖閿濆鈷戦悹鍥ㄧ叀椤庢鏌h箛鏂垮摵闁诡噯绻濋弫鎾绘偐閼艰埖鎲伴梻渚€娼ц墝闁哄懏绮撳畷鎴﹀幢濞戞瑧鍘遍柣蹇曞仜婢т粙鍩ユ径瀣ㄤ簻闊洢鍎茬€氾拷闂傚倸鍊搁崐鎼佸磹瀹勬噴褰掑炊椤掑鏅悷婊冪箻閸┾偓妞ゆ帊鑳堕埢鎾绘煛閸涱垰孝闁伙絽鍢茶灒闁煎鍊楅惁鍫濃攽椤旀枻渚涢柛妯绘倐楠炴劙宕橀瑙f嫼闂佸憡绋戦敃銉﹀緞閸曨垱鐓曢悗锝庡亝瀹曞矂鏌熼搹顐e磳鐎规洜枪铻栧ù锝呮惈瀵即姊绘繝搴′簻婵炴潙瀚濠囨嚍閵壯屾锤闂佸搫绋侀悘鎰版偡閹靛啿鐗氶梺鍛婃处閸橀箖鎮¢埀顒勬⒑閸撗呭笡闁绘濞€瀵濡搁妷銏℃杸闂佺硶鍓濋敋婵炲拑缍佸娲传閸曨剦妫ら梺绋款儍閸婃繂顕f繝姘╅柕澶堝灪椤秹姊洪幆褎绂嬮柛瀣椤㈡棃鏁撻敓锟�婵犵數濮烽弫鍛婃叏閻戣棄鏋侀柟闂寸绾剧粯绻涢幋娆忕仾闁稿鍊濋弻鏇熺箾瑜嶉崯顐︽倶婵犲洦鍊甸柛蹇擃槸娴滈箖姊洪崨濠冨闁告挻鐟︾粋宥夋焼瀹ュ棌鎷洪梺鍛婄☉閿曪絿娆㈤柆宥嗙厱闁绘ê鍟块崫娲煏閸℃鍤囩€殿喖顭锋俊鐑芥晜閹冪闂傚倷鑳剁划顖炲垂閸洘鏅濋柍杞拌閺嬫棃鏌¢崘銊モ偓鑽ゅ婵傚憡鐓冪憸婊堝礈閻旈鏆﹂柛妤冨亹濡插牊绻涢崱妯虹仴妤犵偞顨嗙换婵堝枈濡椿娼戦梺鎼炲妿閺佽鐣烽幋锕€绠涙い鏃囧Г濞堟澘鈹戦悙鏉戠仧闁搞劍妞介幃锟犳偄閸濄儳鐦堥梺鍓茬厛閸嬪懐浜告导瀛樺€垫慨妯煎亾鐎氾拷.

SCISSCIAHCI

